- 16 Posts
- 12 Comments
Joined 1 year ago
Cake day: June 14th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.


 1·9 months ago
1·9 months agoagreed, it’ll just be automated and even faster now
That’s a very misleading title, since “battles” here is referring to survey results and not actual legal battles. The results make sense though. AI will probably generate the most popular kind of post because that’s what has the most representation in its training data.
The main issue here is what is “popular” changes over time, and is directly related to what is available to the public. So if AI floods the internet with the same style of posts because it’s currently the most popular, that style will quickly become boring, and using AI to get clicks will essentially lead to it writing itself into obsolescence. Until it gets trained or fine tuned on a new dataset which includes its own results, which leads to a separate issue where the training data is objectively bad.
it’s a key smash
 4·10 months ago
4·10 months agoi see what you did their

 25·1 year ago
25·1 year agoThere’s a difference between using AI as a tool and using it as a solution. Though knowing how this society works, it’ll start off as a tool like now, and soon enough the higher ups will wonder why humans are even necessary in the process, especially when they need to be paid, and against everyone else’s objections they’ll get rid of the human verification part and use only AI, and when things go wrong the people in charge will go “who could have seen it coming?”
The US copyright office says this on their website
Uploading or downloading works protected by copyright without the authority of the copyright owner is an infringement of the copyright owner’s exclusive rights of reproduction and/or distribution.
If the company downloaded books without buying them to train their AI, that’s copyright infringement
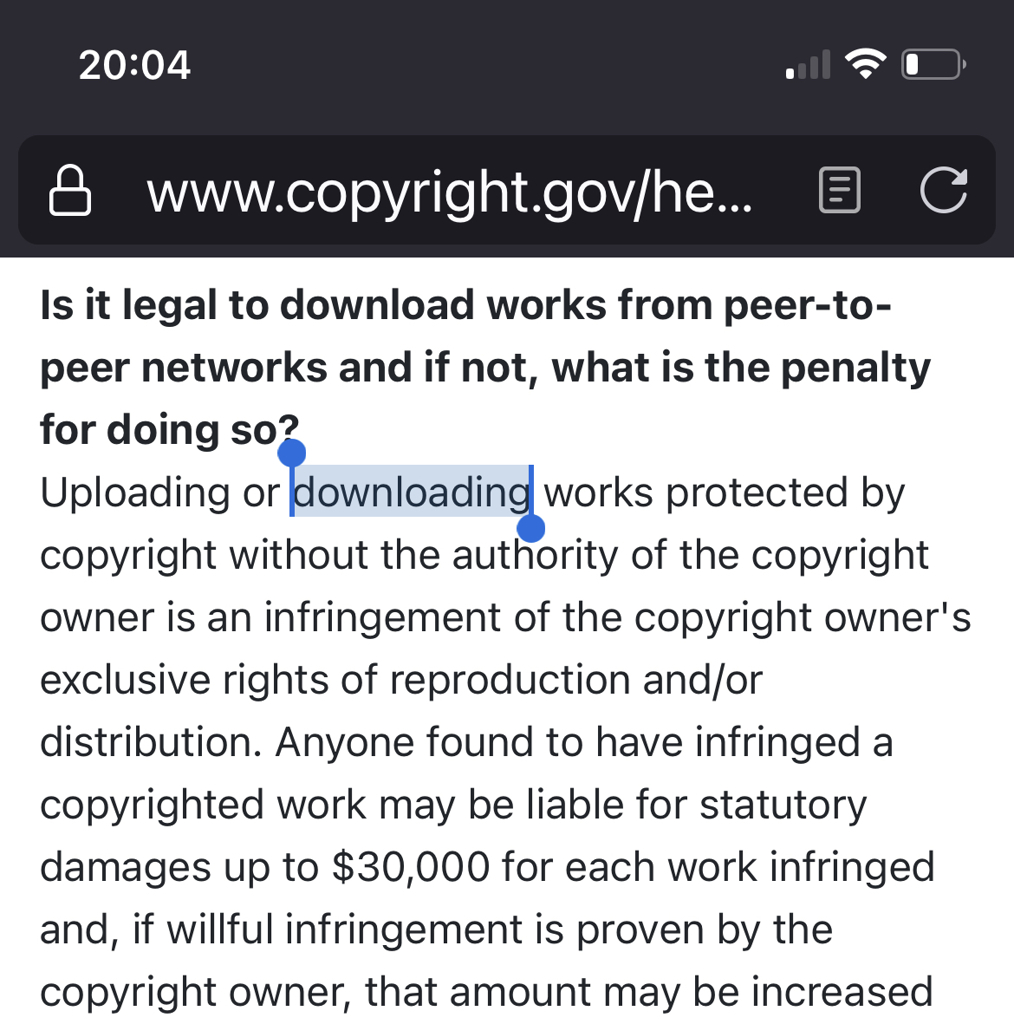



The uploader is the infringing party, not the downloader.
an exclusive right of the copyright holder is the right to duplicate their work. downloading IS illegal because you’re creating an unauthorized duplicate of the work on your machine. your duplicate is distinct from the duplicate that someone else had created and uploaded. it’s just very hard to get caught downloading, and it’s not very cost effective for companies to pursue since they would only stop one person. that’s why most companies like the RIAA targeted torrents for their lawsuits, because they could easily see the ip addresses (which is why you should always use a vpn when torrenting) and because they could shut down uploaders. but downloading itself is still very illegal
My work does not violate copyright, unless I use a substantial part of the other works.
like I said, the AI is not a violation (probably, unless the courts later disagree), it’s proof that unauthorized duplication of copyrighted works has occurred, and that is illegal
There was still copyright infringement because the company probably downloaded the text (which created another copy) and modified it (alteration is also protected by copyright) before using it as training data. If you write an original novel and admit that you had pirated a bunch of novels to use for reference, those novels were still downloaded illegally even if you’ve deleted them by now. The AI isn’t copyright infringement itself, it’s proof that copyright infringement has happened.
But personally I don’t think the actual laws will matter so much as which side has the better case for why they will lead to more innovation and growth for the economy.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
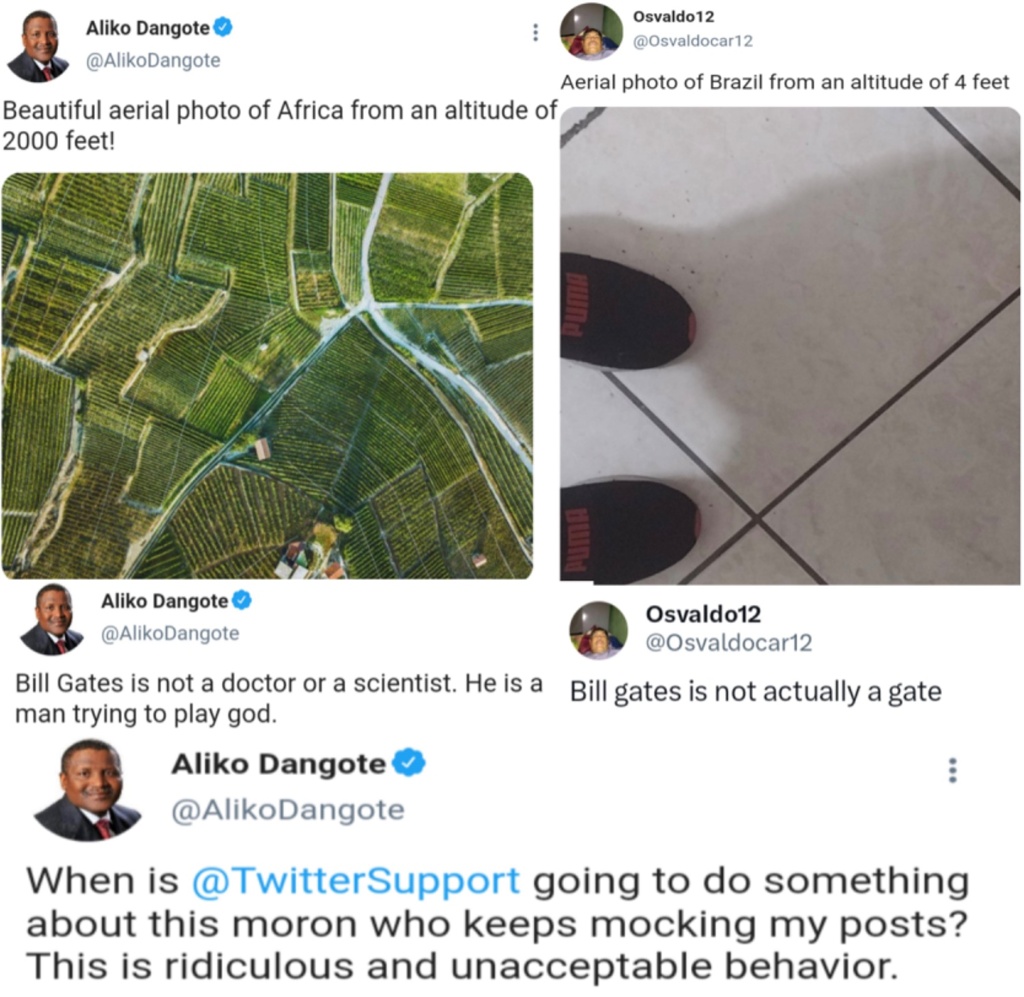{kind=link}
{kind=link}
{kind=link}
{kind=link}
 3·1 year ago
3·1 year agothey do have some good starters in that sub
{kind=link}
{kind=link}
👻👻👻